

How To Find Duplicate Records In Unix
Have you ever run into text files with repeated lines and indistinguishable words? Maybe you regularly work with command output and want to filter those for singled-out strings. When it comes to text files and the removal of redundant information in Linux, the uniq control is your best bet.
In this article, we will discuss the uniq command in-depth, forth with a detailed guide on how to utilize the command to remove duplicate lines from a text file.
What Is the uniq Command?
The uniq command in Linux is used to brandish identical lines in a text file. This control tin can be helpful if you desire to remove duplicate words or strings from a text file. Since the uniq command matches adjacent lines for finding redundant copies, information technology but works with sorted text files.
Luckily, you can pipe the sort command with uniq to organize the text file in a manner that is compatible with the command. Apart from displaying repeated lines, the uniq command can also count the occurrence of duplicate lines in a text file.
How to Use the uniq Control
There are diverse options and flags that y'all tin can use with uniq. Some of them are basic and perform uncomplicated operations such as printing repeated lines, while others are for advanced users who often piece of work with text files on Linux.
Bones Syntax
The basic syntax of the uniq control is:
uniq pick input output ...where option is the flag used to invoke specific methods of the command, input is the text file for processing, and output is the path of the file that will store the output.
The output argument is optional and can be skipped. If a user doesn't specify the input file, uniq takes information from the standard output equally the input. This allows a user to pipage uniq with other Linux commands.
Example Text File
We'll be using the text file duplicate.txt as the input for the command.
127.0.0.1 TCP
127.0.0.one UDP
Exercise catch this
DO Grab THIS
Don't match this
Don't take hold of this
This is a text file.
This is a text file.
THIS IS A TEXT FILE.
Unique lines are really rare.
Note that we take already sorted this text file using the sort command. If y'all are working with some other text file, you lot can sort it using the following control:
sort filename.txt > sorted.txt Remove Duplicate Lines
The nearly bones use of uniq is to remove repeated strings from the input and print unique output.
uniq duplicate.txt Output:
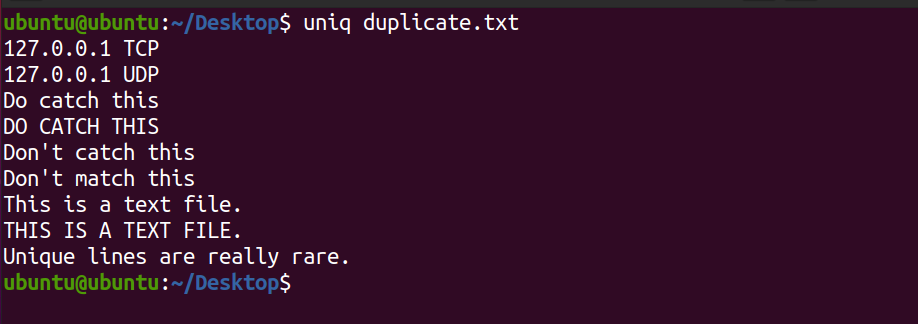
Detect that the system doesn't display the 2d occurrence of the line This is a text file. Besides, the aforementioned command only prints the unique lines in the file and doesn't touch the content of the original text file.
Count Repeated Lines
To output the number of repeated lines in a text file, use the -c flag with the default command.
uniq -c indistinguishable.txt Output:
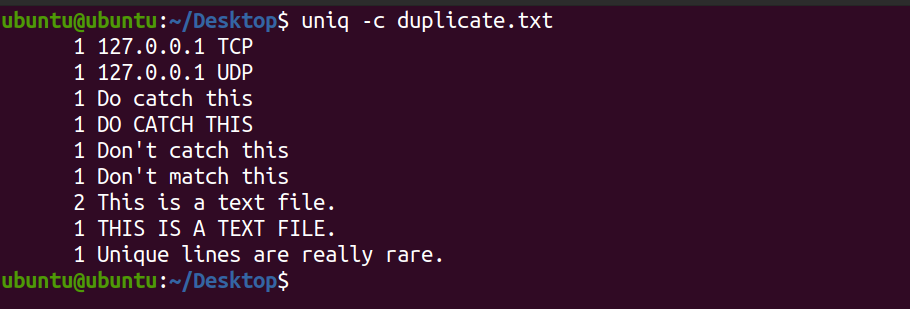
The organization displays the count of each line that exists in the text file. You tin come across that the line This is a text file occurs two times in the file. By default, the uniq command is case-sensitive.
Print Merely Repeated Lines
To only impress duplicate lines from the text file, employ the -D flag. The -D stands for Duplicate.
uniq -D indistinguishable.txt The system will display output as follows.
This is a text file.
This is a text file. Skip Fields While Checking for Duplicates
If you desire to skip a certain number of fields while matching the strings, y'all can use the -f flag with the command. The -f stands for Field.
Consider the following text file fields.txt.
192.168.0.1 TCP
127.0.0.1 TCP
354.231.1.1 TCP
Linux FS
Windows FS
macOS FS To skip the first field:
uniq -f 1 fields.txt Output:
192.168.0.1 TCP
Linux FS The aforementioned command skipped the first field (the IP addresses and Os names) and matched the 2nd word (TCP and FS). Then, it displayed the first occurrence of each lucifer as the output.
Ignore Characters When Comparing
Like skipping fields, you tin skip characters as well. The -southward flag allows yous to specify the number of characters to skip while matching duplicate lines. This feature helps when the data yous are working with is in the form of a list equally follows:
1. Commencement
2. 2nd
3. Second
4. Second
5. Tertiary
six. Third
7. Fourth
8. 5th To ignore the start two characters (the list numberings) in the file listing.txt:
uniq -southward 2 list.txt Output:
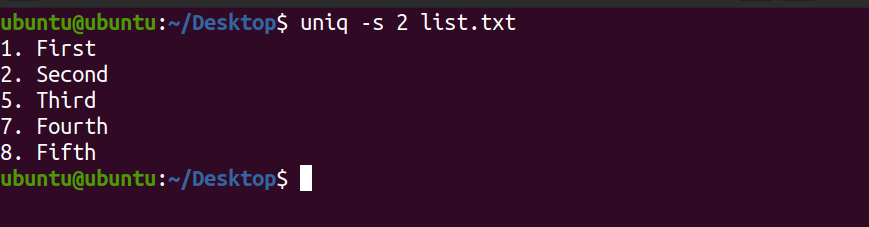
In the output above, the offset two characters were ignored and the rest of them were matched for unique lines.
Check Starting time N Number of Characters for Duplicates
The -due west flag allows you to check only a stock-still number of characters for duplicates. For example:
uniq -w 2 indistinguishable.txt The aforementioned command will only match the first ii characters and will print unique lines if whatever.
Output:
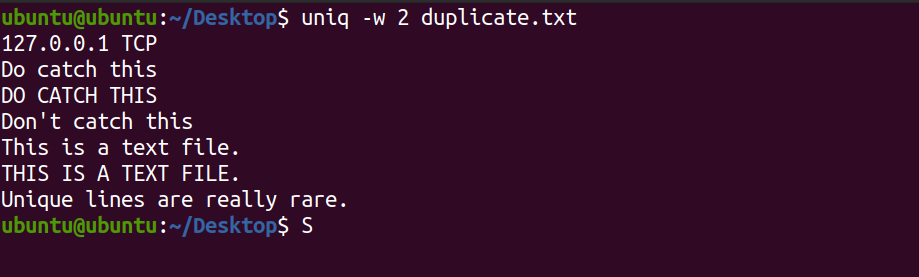
Remove Case Sensitivity
Equally mentioned above, uniq is example-sensitive while matching lines in a file. To ignore the graphic symbol instance, use the -i pick with the command.
uniq -i duplicate.txt You lot will run across the post-obit output.
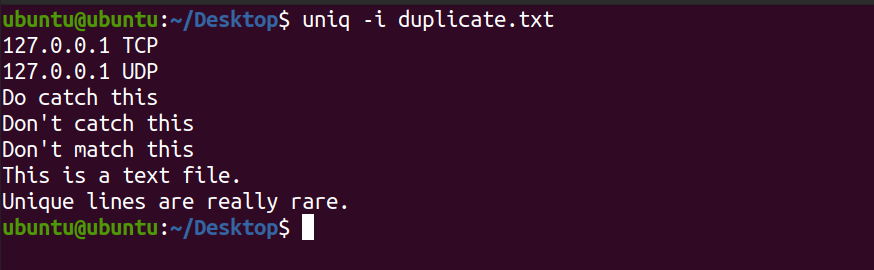
Find in the output above, uniq did not display the lines Exercise CATCH THIS and THIS IS A TEXT FILE.
Send Output to a File
To transport the output of the uniq control to a file, you tin can use the Output Redirection (>) character as follows:
uniq -i duplicate.txt > otherfile.txt While sending an output to a text file, the organization doesn't display the output of the command. You tin cheque the content of the new file using the true cat control.
cat otherfile.txt You lot can also use other ways to transport command line output to a file in Linux.
Analyzing Duplicate Data With uniq
Nigh of the time while managing Linux servers, you lot will exist either working on the terminal or editing text files. Therefore, knowing how to remove redundant copies of lines in a text file can be a great asset to your Linux skill fix.
Working with text files can be frustrating if y'all don't know how to filter and sort text in a file. To make your work easier, Linux has several text editing commands such as sed and awk that allow you lot to work efficiently with text files and command-line outputs.
About The Writer 

Source: https://www.makeuseof.com/how-to-find-duplicate-data-in-a-linux-text-file-with-uniq/
Posted by: hallettpasper.blogspot.com
0 Response to "How To Find Duplicate Records In Unix"
Post a Comment